原文链接:https://blog.csdn.net/weixin_44648900/article/details/105196981
疫情期间无聊突发奇想想要做一个在线考试系统,目前已完成数据库设计,开始编写爬虫爬取试题数据,目标网站如下,获取内容包括:考点,试题,答案选项,答案,解析。考点字段的获取便于以后系统个性化推荐的需要。🚔
去除网页里获取时候遇到的脏数据
查看网页的时候发现这个东西,可能是他们后台有其他用途,由于直接匹配字段不方便,先把所有网页文本先获取再把class为this_jammer等中内容获取为停用词表,爬取的试题文本去掉这些脏数据就OK了。
下面保存脏数据表的函数
#-*-coding:utf-8-*-
import requests
from bs4 import BeautifulSoup
# import codecs
def get_url(target_url, server, headers):
req = requests.get(target_url, headers=headers)
bf = BeautifulSoup(req.text)
div = bf.find_all('div', class_='questions_col')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
cheak_parsing_url = []
for each in a:
if each.string == "查看解析":
full_url = server + each.get('href')
cheak_parsing_url.append(full_url)
print(cheak_parsing_url)
return cheak_parsing_url
def change_page(target_url, server, headers):
req = requests.get(target_url, headers=headers)
bf = BeautifulSoup(req.text)
div = bf.find_all('div', class_='fenye')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
full_url = None
for each in a:
if each.string == "下一页":
full_url = server + each.get('href')
print(full_url)
else :
continue
return full_url
def get_html(url_list, file_path, headers):
for url in url_list:
req = requests.get(url, headers=headers)
content = req.content.decode('utf-8','ignore')
bf = BeautifulSoup(content, fromEncoding="gb18030")
del_text = bf.find_all(class_=["this_jammer", "hidejammersa", "jammerd42"])
for i in del_text:
if i:
new_tag = ""
try:
i.string.replace_with(new_tag)
except:
pass
texts = bf.find_all('div', class_= 'answer_detail')
try:
texts = texts[0].text.replace('\xa0', '')
texts = texts.replace(" ", "")
except:
pass
try:
texts = texts.replace("\n", '')
except:
pass
print(texts)
contents_save(file_path, texts)
def contents_save(file_path, content):
"""
:param file_path: 爬取文件保存路径
:param content: 爬取文本文件内容
:return: None
"""
with open(file_path, 'a', encoding="utf-8", errors='ignore') as f:
try:
f.write(content)
except:
pass
f.write('\n')
def get_category(target_url, server, headers):
req = requests.get(target_url, headers=headers)
bf = BeautifulSoup(req.text)
div = bf.find_all('div', class_='shiti_catagory frame')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
category = []
for each in a:
full_url = server + each.get('href')
category.append(full_url)
print(category)
return category
if __name__ == "__main__":
main_url = "https://tiku.21cnjy.com/tiku.php?mod=quest&channel=8&xd=3"
server = "https://tiku.21cnjy.com/"
save_dir = "/Users/lidongliang/Desktop/爬虫/data"
subject_file = "1.txt"
file_path = save_dir + '/' + subject_file
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept-Encoding': 'gzip'}
categorys = get_category(main_url, server, headers)
for category_url in categorys:
counting = 0
target_url = category_url
while counting < 100:
cheak_parsing_url = get_url(target_url, server, headers)
get_html(cheak_parsing_url, file_path, headers)
target_url = change_page(target_url, server, headers)
if target_url == None:
break
counting += 1
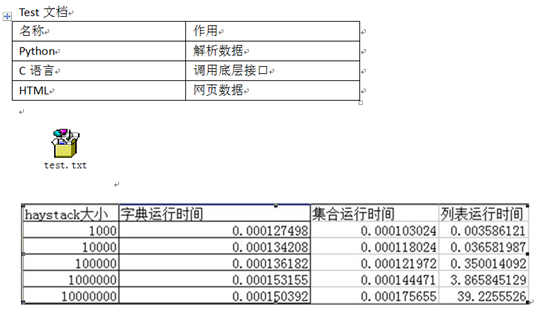
运行初步结果如下:
对文本进行正则匹配获取文本指定字段并保存到数据库
import re
import pymysql
w1 = 'A.'
w2 = 'B.'
w3 = 'C.'
w4 = 'D.'
w5 = '答案'
w6 = '解析试题分析:'
w7 = '考点'
def get_txt():
with open("/Users/lidongliang/Desktop/爬虫/data/1.txt", "r") as f:
txt = f.readlines()
return txt
def fen(txt):
# buff = txt.replace('\n','')
timu = re.compile('^' + '(.*?)' + w1, re.S).findall(txt)
A = re.compile(w1 + '(.*?)' + w2, re.S).findall(txt)
B = re.compile(w2 + '(.*?)' + w3, re.S).findall(txt)
C = re.compile(w3 + '(.*?)' + w4, re.S).findall(txt)
D = re.compile(w4 + '(.*?)' + w5, re.S).findall(txt)
daan = re.compile(w5 + '(.*?)' + w6, re.S).findall(txt)
jiexi = re.compile(w6 + '(.*?)' + w7, re.S).findall(txt)
kaodian = re.compile(w7 + '(.*?)' + '\Z', re.S).findall(txt)
timu.extend(A)
timu.extend(B)
timu.extend(C)
timu.extend(D)
timu.extend(daan)
timu.extend(jiexi)
timu.extend(kaodian)
# print(timu)
try:
tg = timu[0]
xx = ("A:" + timu[1] + "B:" + timu[2] + "C:" + timu[3] + "D:" + timu[4])
da = timu[5]
fx = timu[6]
kd = timu[7]
except:
tg = '1'
xx = '1'
da = '1'
fx = '1'
kd = '1'
con = pymysql.connect(host='localhost', user='root', passwd='00000000', db='login_test_1', charset='utf8')
cursor = con.cursor()
sql = "insert into question_info(tg,xx,da,fx,kd) values('%s','%s','%s','%s','%s')" \
% (tg, xx, da, fx, kd)
cursor.execute(sql)
con.commit()
if __name__ == "__main__":
txt = get_txt()
for i in txt:
fen(i)
print("done")
最后结果: