原因:
目录的所属组,所属用户属于root, 导致FTP无法上传, 修改组和所属用户为www即可
chgrp -fR www ./*
chown -fR www ./*
连接不到 ftp 了 查看了很多原因 最后 更改文件夹权限 就可以了 更改为root然后就正常连接到了 或者更改文件夹权限 就可以正常使用了
学习笔记
原因:
目录的所属组,所属用户属于root, 导致FTP无法上传, 修改组和所属用户为www即可
chgrp -fR www ./*
chown -fR www ./*
连接不到 ftp 了 查看了很多原因 最后 更改文件夹权限 就可以了 更改为root然后就正常连接到了 或者更改文件夹权限 就可以正常使用了只需要把公式图片用鼠标拖动到工具内,就能一键转成 LaTex 公式。
写论文、做研究时,最让你头疼的是什么?想必公式编辑会榜上有名。那么有没有便捷的方法进行公式编辑呢?这里推荐一款神器,它使用 PyTorch Lightning 可将 LaTeX 数学方程的图像映射到 LaTeX 代码。
它的效果是这样的,输入一张带公式的图片,它能转换成 LaTeX 代码形式:

而它的名字也是很直接的,就叫做「Image to LaTex Converter」,把产品功能写在了明面上。

项目地址:https://github.com/kingyiusuen/image-to-latex
此前,很多人都在用 Mathpix Snip,这个工具虽然好用,但是只能提供 50 次免费转换。之后,一位中国开发者也创建了一款类似工具「Image2LaTeX」,用户输入公式截图即可以自动将其对应的 LaTex 文本转换出来。效果也虽好,不过也只是提供了 1000 次从文档中提取公式的能力。
此次项目的创建者为明尼苏达大学双城分校计量心理学博士生 King Yiu Suen,他本科毕业于香港中文大学,致力于研究评估心理测试和教育评估的统计学方法,以及测试响应数据的建模。
该项目为何能够一键转换成 LaTex 公式?这要都得益于背后使用的数据集和模型。
项目背后的数据集与模型
作者也对打造过程进行了详细的介绍。2016 年,在 Yuntian Deng 等作者合著的一篇 OCR 主题论文《What You Get Is What You See: A Visual Markup Decompiler》中,他们介绍了叫做「im2latex-100K」的模型(原始版本和预处理版本),这是一个由大约 100K LaTeX 数学方程图像组成的数据集。
作者使用该数据集训练了一个模型,使用 ResNet-18 作为具有 2D 位置编码的编码器,使用 Transformer 作为具有交叉熵损失的解码器。这个过程类似于《Full Page Handwriting Recognition via Image to Sequence Extraction》Singh et al. (2021) 中描述的方法,不过作者只使用 ResNet up to block 3 来降低计算成本,并且去掉了行号编码,因为它不适用于这个问题。

Singh et al. (2021)论文中的系统架构。
最初,作者使用预处理数据集来训练模型,因为预处理图像被下采样到原始大小的一半以提高效率,而且分组并填充为相似的大小以方便批处理。但结果表明,这种严格的预处理被证明是一个巨大的限制。尽管该模型可以在测试集(其预处理方式与训练集相同)上取得合格的性能,但它并不能很好地泛化到数据集之外的图像,这很可能是因为其他图像质量、填充和字体大小与数据集中的图像不同。
使用相同数据集尝试解决相同问题的其他人也发现了这种现象。下图这位开发者试图从论文中裁剪图像,图像与数据集中的图像大小相似。但即使对于简单的公式,输出也会完全失败:

为此,作者使用了原始数据集并在数据处理 pipeline 中包含了图像增强(例如随机缩放、高斯噪声)以增加样本的多样性。此外,作者没有按大小对图像进行分组,而是进行了均匀采样并将它们填充为批次中最大图像的大小,以便模型必须学习如何适应不同的填充大小。
作者在使用数据集中遇到的其他问题包括:
不过,该项目也有一些可能需要改进的地方:
作者使用的是 Google Colab,计算资源有限,因此并没有做到以上这些。
项目的使用与部署
# 在项目设置方面:首先你需要将该项目克隆到计算机,并将命令行放置到库文件夹中:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
# 然后,创建一个名为 venv 的虚拟环境并安装所需的软件包:
make venv
make install-dev
# 在数据预处理方面:执行如下命令下载 im2latex-100k 数据集并进行所有预处理任务(图像裁剪可能需要一个小时):
python scripts/prepare_data.py
# 在模型训练方面:启动训练 session 的命令如下:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
# 你可以在 conf/config.yaml 中修改配置,也可以在命令行中修改。
# 在实验跟踪方面:最佳模型 checkpoint 将自动上传到 Weights & Biases (W&B)(在训练开始前你需要先进行注册或登录 W&B )。如下是从 W&B 下载训练模型 checkpoint 的示例命令:
python scripts/download_checkpoint.py RUN_PATH
# 将 RUN_PATH 替换为运行的路径,运行路径格式为 < entity>/<project>/<run_id>。如果你想查找特定实验运行的运行路径,请转到 dashboard 中的 Overview 选项卡进行查看。
# 例如,你可以使用如下命令下载最佳运行:
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
# checkpoint 将被下载到项目目录下一个名为 artifacts 的文件夹中。
# 测试和持续集成方面:以下工具可用于 lint 代码库:
# isort:对 Python 脚本中的 import 语句进行排序和格式化;
# black:遵循 PEP8 的代码格式化程序;
# flake8:在 Python 脚本中报告风格问题的代码检查器;
# mypy:在 Python 脚本中执行静态类型检查。
# 使用下面的命令来运行所有的检查和格式化程序:
make lint
# 在部署方面:训练好的模型通过创建的 API 进行预测,启动和运行服务器命令如下:
make api
# 要运行 Streamlit 应用程序,请使用以下命令创建一个新的终端窗口:
make streamlit
# 应用程序应该在浏览器中自动打开,你也可通过 http://localhost:8501 / 进行查看。想让这个应用程序运行,你还需要下载实验运行的工件,启动并运行 API。
# 为 API 创建一个 Docker 映像:
make docker<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>在指定div中浏览PDF</title>
<!--在此引入bootstrap只为初始化样式div样式-->
<link rel="stylesheet" href="css/bootstrap.min.css" />
<style>
/* 添加样式是为了实现全屏效果 */
html,body{
height: 100%;
overflow: hidden;
}
#example1{
height: 100%;
}
.pdfobject-container{
/* height: 500px; */
}
.pdfobject{
/* border: 1px solid #666; */
}
</style>
</head>
<body>
<div id="example1"></div>
<script type="text/javascript" src="js/pdfobject.min.js"></script>
<script>
// 我的pdf文件放在项目的pdf文件夹下,名字叫做Java.pdf,指定PDF从20页开始阅读
PDFObject.embed("pdf/Java.pdf", "#example1", {page: "20"});
</script>
</body>
</html>How to embed a PDF without using JavaScript
方式一:
<embed src="/pdf/sample-3pp.pdf#page=2" type="application/pdf" width="100%" height="100%" />方式二:
<iframe src="/pdf/sample-3pp.pdf#page=2" width="100%" height="100%">
</iframe>方式三:
<object data="/pdf/sample-3pp.pdf#page=2" type="application/pdf" width="100%" height="100%">
<b>Example fallback content</b>: This browser does not support PDFs. Please download the PDF to view it:
<a href="/pdf/sample-3pp.pdf">Download PDF</a>.
</object>方式四:
<object data="/pdf/sample-3pp.pdf#page=2" type="application/pdf" width="100%" height="100%">
<iframe src="/pdf/sample-3pp.pdf#page=2" width="100%" height="100%" style="border: none;">
This browser does not support PDFs. Please download the PDF to view it:
<a href="/pdf/sample-3pp.pdf">Download PDF</a>
</iframe>
</object>视图表单部分
<?php $form = \yii\widgets\ActiveForm::begin() ?>
<?=$form->field($model,'username')->textInput() ?>
<?=$form->field($model,'hobby')->checkboxList(['1'=>'篮球','2'=>'足球','3'=>'游戏','4'=>'读书'])?>
<?=\yii\helpers\Html::submitButton('保存',['class'=>'btn btn-primary'])?>
<?php \yii\widgets\ActiveForm::end()?>
模型部分
public function beforeSave($insert) {
if($this->hobby) {
$this->hobby = implode(',',$this->hobby);
}
return parent::beforeSave($insert); // TODO: Change the autogenerated stub
}
public function afterFind() {
$this->hobby = explode(',',$this->hobby);
parent::afterFind();
}yii2.0 的 多选框实现方法
第一种:
ActiveForm::checkboxList();
优点:可以将全部数据生成多选框,自带验证
$form->field($model, 'username')->checkboxList(ArrayHelper::map($data,'id', 'customer_name'));
第二种:
ActiveForm::checkbox();
优点:只生成一个多选框,自带验证
$form->field($model, 'username')->checkbox(ArrayHelper::map($data,'id', 'customer_name'));
第三种:
Html::activeCheckbox();
Html::activeCheckbox($model, 'username', ArrayHelper::map($data,'id', 'customer_name'));
第四种:
Html::activeCheckboxList();
Html::activeCheckboxList($model, 'username', ArrayHelper::map($data,'id', 'customer_name'));多选题的给分原则是多选错选不得分,部分选对得部分分
$q_answer = 'A,B,C'; //正确答案
$s_answer = 'A,D'; //学生答案
$q_answer = explode(',',$q_answer);
$s_answer = explode(',',$s_answer);
$count = count($q_answer);
$score = 6;
if(count(array_diff($s_answer,$q_answer)) > 0)
{
$real_score = 0;
}
else
{
$real_score = $score * count(array_intersect($q_answer,$s_answer)) / $count;
}
echo $real_score;
运行结果为:0
下面是网上看到的Latex在线编辑器:
1.吴文中公式编辑器:https://latex.91maths.com/s/?JTVDb3ZlcnJpZ2h0YXJyb3clN0JBQiU3RA==
2.LaTeX公式编辑器:https://www.latexlive.com/home##
3.Equation Editor for online mathematics:https://editor.codecogs.com/
4.HotMath:http://www.hostmath.com/Default.aspx
Yii2的Cookie主要是通过yii/web/Request和yii/web/Response进行操作的,Yii2的Session比较简单 ,直接通过/Yii::$app->session进行操作就好了。本文给大家介绍COOKIE和SESSION用法,需要的朋友参考下
1、Cookie
Yii2的Cookie主要是通过yii/web/Request和yii/web/Response进行操作的 ,通过/Yii::$app->response->getCookies()->add()添加Cookie,通过/Yii::$app->request->cookies读取Cookie.
1)添加一个Cookie
<?php
//第一种方法
$cookie= new/yii/web/Cookie();
$cookie-> name = 'smister';//cookie的名称
$cookie-> expire = time() + 3600; //存活的时间
$cookie-> httpOnly = true; //无法通过js读取cookie
$cookie-> value = 'cookieValue'; //cookie的值
Yii::$app->response->getCookies()->add($cookie);
//第二种方法
$cookie= new/yii/web/Cookie([‘name' => ‘smister',‘expire' => time() + 3600,‘httpOnly ' => true,‘value' => ‘cookieValue']);
Yii::$app->response->getCookies()->add($cookie);
?>2) 读取一个Cookie
<?php
$cookie= Yii::$app->request->cookies;//返回一个/yii/web/Cookie对象
$cookie->get(‘smister');//直接返回Cookie的值
$cookie->getValue(‘smister'); //$cookie[‘smister'] 其实这样也是可以读取的
//判断一个Cookie是否存在
$cookie->has(‘smister');//读取Cookie的总数
$cookie->count();//$cookie->getCount();跟count一样
?>3) 删除Cookie
<?php
$cookie= Yii::$app->request->cookies->get(‘smister');
//移除一个Cookie对象
Yii::$app->response->getCookies()->remove($cookie);
//移除所有Cookie,目前好像不太好使
Yii::$app->response->getCookies()->removeAll();
?>4) 注意
对Cookie进行增删改时调用的response , 对Cookie读取时使用的是Request
2、Session
Yii2的Session比较简单 ,直接通过/Yii::$app->session进行操作就好了
1) 添加一个session
<?php
$session= Yii::$app->session;
$session->set('smister_name', 'myname');
$session->set('smister_array',[1,2,3]);
?>2) 读取一个session
<?php
$session= Yii::$app->session;
//读取一个Session
$session->get('smister_name);
?>3) 删除Session
<?php
$session= /Yii::$app->session;
//删除一个session
$session->remove(‘smister_name');
//删除所有session
$session->removeAll();
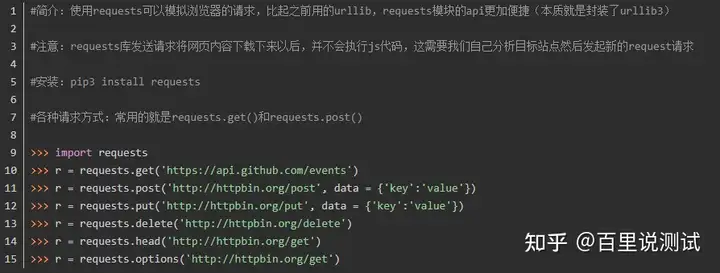
?>简介:使用requests可以模拟浏览器的请求,比起之前用的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
安装:pip3 install requests
各种请求方式:常用的就是requests.get()和requests.post()
如果你想学习自动化测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的自动化测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
1、基本请求

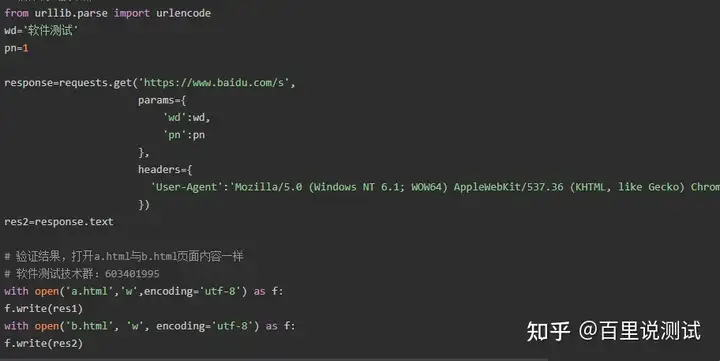
2、带参数的GET请求->params
在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容

如果查询关键词是中文或者有其他特殊符号,则不得不进行url编码
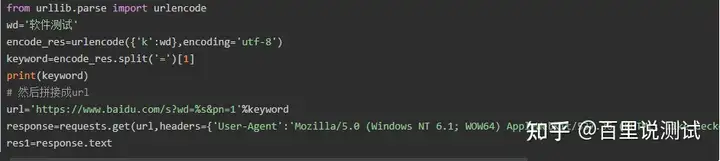
上述操作可以用requests模块的一个params参数搞定,本质还是调用urlencode
3、带参数的GET请求->headers
通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下

添加headers(浏览器会识别请求头,不加可能会被拒绝访问,比如访问
https://www.zhihu.com/explore)
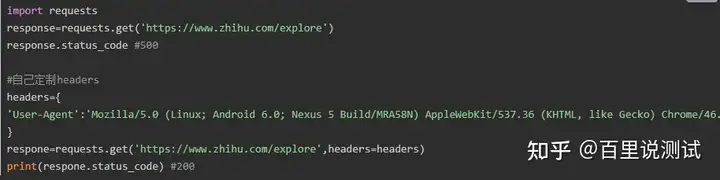
4、带参数的GET请求->cookies
登录github,然后从浏览器中获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名密码
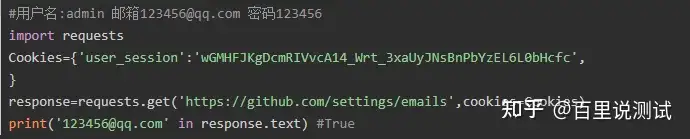
GET请求
HTTP默认的请求方法就是GET
1.没有请求体
2.数据必须在1K之内
3.GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
POST请求
1.数据不会出现在地址栏中
2.数据的大小没有上限
3.有请求体
4.请求体中如果存在中文,会使用URL编码!
#!!!requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
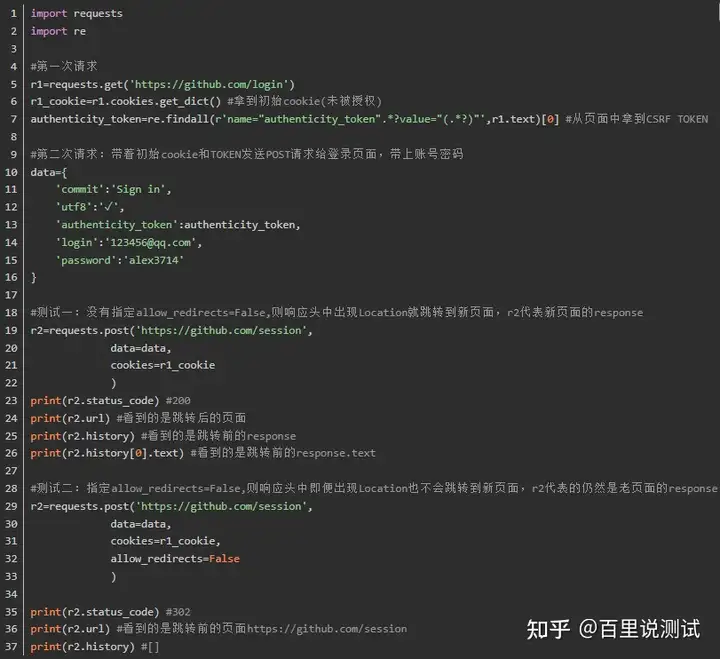
2、发送POST请求,模拟浏览器的登录行为
对于登录来说,应该输错用户名或密码然后分析抓包流程,用脑子想一想,输对了浏览器就跳转了,还分析个毛线,累死你也找不到包
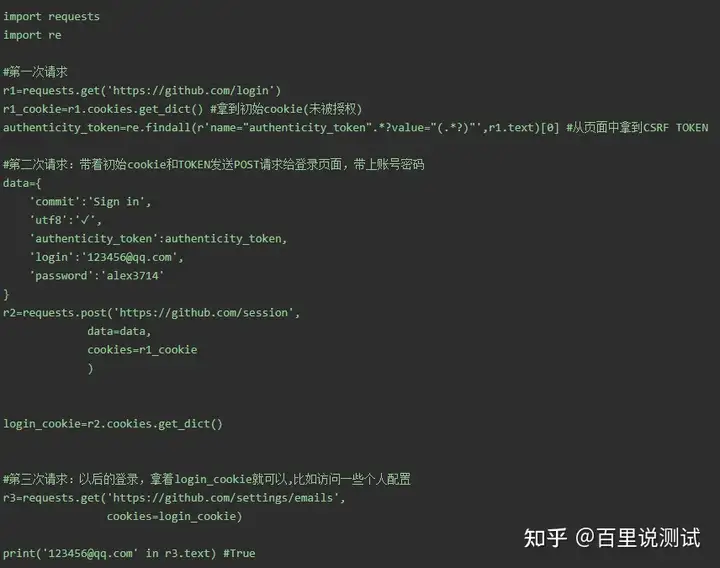
一 目标站点分析
然后输入错误的账号密码,抓包
发现登录行为是post提交到:
而且请求头包含cookie
而且请求体包含:
commit:Sign in
utf8:✓
authenticity_token:lbI8IJCwGslZS8qJPnof5e7ZkCoSoMn6jmDTsL1r/m06NLyIbw7vCrpwrFAPzHMep3Tmf/TSJVoXWrvDZaVwxQ==
login:admin
password:123456
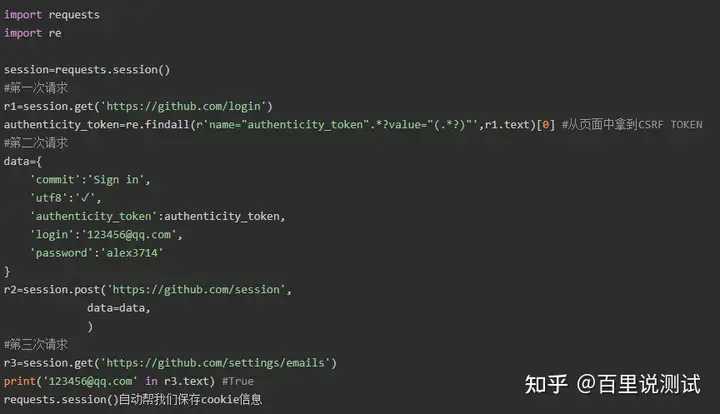
二 流程分析
先GET:https://github.com/login拿到初始cookie与authenticity_token
返回POST:
https://github.com/session, 带上初始cookie,带上请求体(authenticity_token,用户名,密码等)
最后拿到登录cookie
ps:如果密码时密文形式,则可以先输错账号,输对密码,然后到浏览器中拿到加密后的密码,github的密码是明文
3、补充
1、response属性
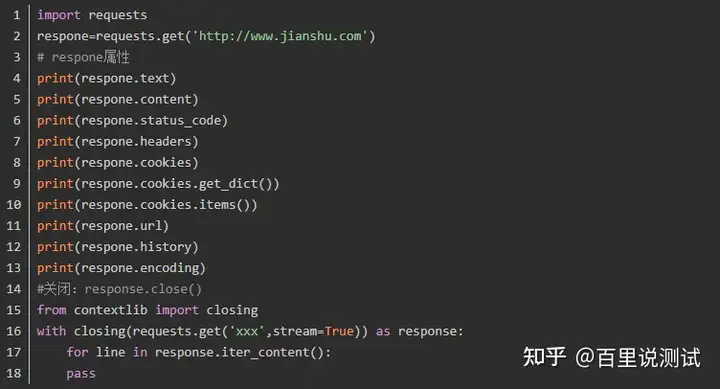
2、编码的问题

3、获取二进制数据
import requests
response=requests.get('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=123456&di=712e4ef3ab258b36e9f4b48e85a81c9d&imgtype=0&src=http%3A%2F%2Fc.hiphotos.baidu.com%2Fimage%2Fpic%2Fitem%2F11385343fbf2b211e1fb58a1c08065380dd78e0c.jpg')
with open('a.jpg','wb') as f:
f.write(response.content)
#stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
import requests
response=requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4',
stream=True)
with open('b.mp4','wb') as f:
for line in response.iter_content():
f.write(line)4、解析json
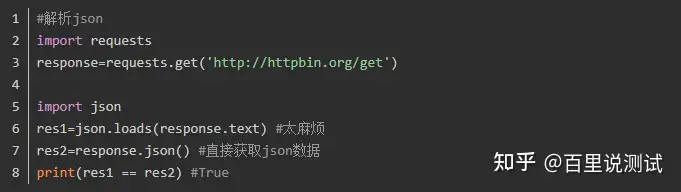
5、Redirection and History
1、SSL Cert Verification
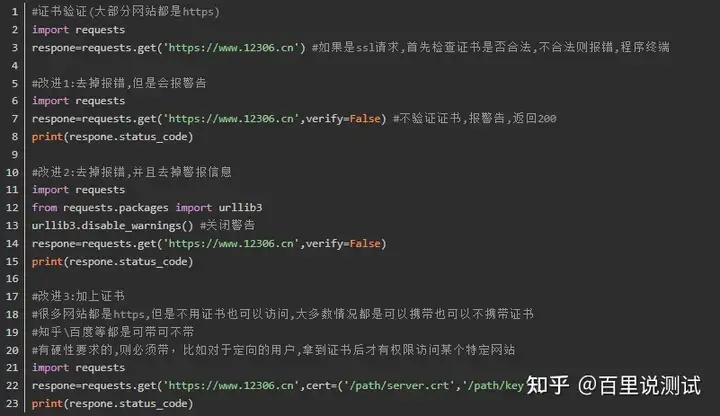
2、使用代理
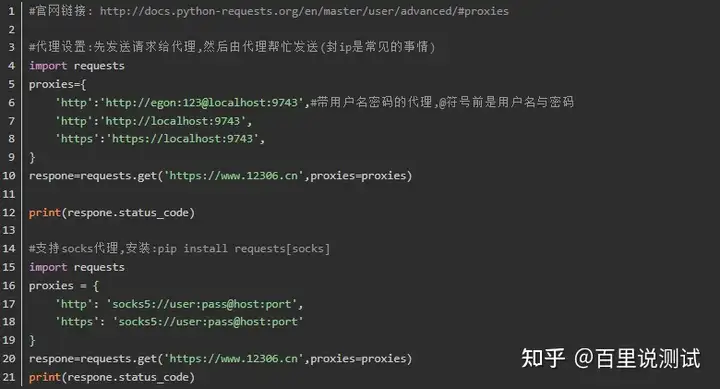
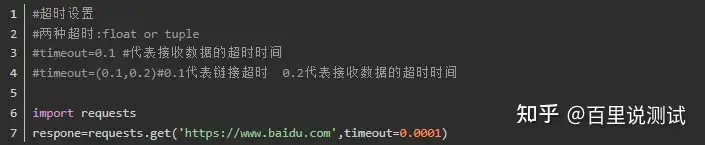
3、超时设置
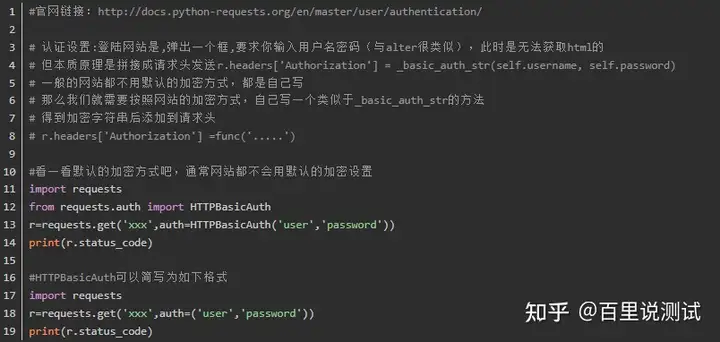
4、认证设置
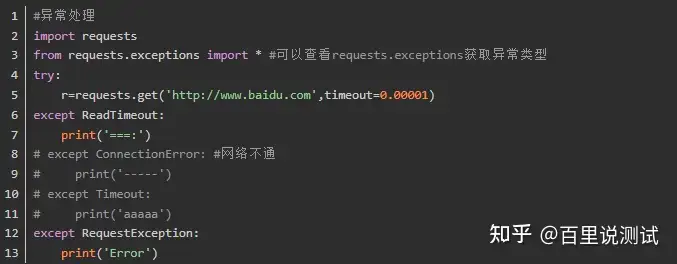
5、异常处理
6、上传文件

Requests 是一个 Python 的一个第三方库,通过发送 HTTP 请求获取响应数据,一般应用于编写网络爬虫和接口测试等。
相比 urllib 库,它语法简单,更容易上手。
官方中文文档地址:Requests: 让 HTTP 服务人类
离线文档下载地址:Requests document download
pip install requests
在使用 requests 模拟发送网络请求之前,先来简单学习一下HTTP和常见的请求方式。
HTTP(HyperText Transfer Protocol ,超文本传输协议)是一个简单的请求/响应协议。即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到请求后,给予相应的响应信息。
1.客户端与服务器端建立连接
2.客户端向服务器端发起请求
3.服务器接受请求,并根据请求返回相应的内容
4.客服端与服务器端连接关闭
客户端和服务器端之间的HTTP连接是一种一次性连接,它限制每次连接只处理一个请求,当服务器返回本次请求的应答后便立即关闭,下次请求再重新建立连接。这样做的好处就是让服务器不会处于一个一直等待的状态,及时释放连接可极大提高服务器的执行效率。
HTTP是一种无状态协议,意思就是服务器不保留与客户端连接时的任何状态。这减轻了服务器的记忆负担,从而保持较快的响应速度。
每种请求方式规定了客户端和服务器端之间不同的信息交换方式。
| 请求方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立或已有资源的修改。 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| PUT | 从客户端向服务器传送数据取代指定的文档的内容。 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 |
| DELETE | 请求服务器删除指定的页面 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
| CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器 |
请求方法GET和POST的区别:
- GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制
- GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
- GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
| 分类 | 分类描述 |
|---|---|
| 1** | 指示信息–服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功–操作被成功接收并处理 |
| 3** | 重定向–需要进一步的操作以完成请求 |
| 4** | 客户端错误–请求包含语法错误或无法完成请求 |
| 5** | 服务器错误–服务器在处理请求的过程中发生了错误 |
常见的状态码:
| 状态码 | 含义 |
|---|---|
| 200 OK | 客户端请求成功 |
| 400 Bad Request | 客户端请求有语法错误,不能被服务器理解 |
| 401 Unauthorized | 请求未经授权,这个状态码必须和 WWW-Authenticate 报头域一起使用 |
| 403 Forbidden | 服务器收到请求,但是拒绝服务 |
| 404 Not Found | 请求资源不存在,eg:输入了错误的URL |
| 500 Internal Server Error | 服务器发生不可预期的错误 |
| 503 Server Unavailable | 服务器当掐你不能处理客户端的请求,一段时间后可能恢复 |
使用 requests 的流程大致可以分为以下三步:
填写method url params等参数➡发起请求➡查看响应结果
使用 requests 发起请求有两种方式,以发起post请求为例:
import requests
# 方式一:
r = requests.request("post","https://www.baidu.com")
print(r.text)
# 方式二:
r = requests.post("https://www.baidu.com")
print(r.text)requests.request(method, url, ...)的 request 是 requests 封装好根据 method 传参的不同而调用对应的请求方法。method 参数的值可以是 get/post/put/delete/head/patch/options 等,对应我们上一节的 HTTP 请求方法。上面的示例代码中方式一和方式二达到的效果都是一样的,但是推荐使用方式一,因为在后面的接口自动化测试中便于参数化,如下:
import requests
method = "get"
url = "https://www.baidu.com"
r = requests.request(method=method, url=url)
print(r.text)requests 发起请求时,支持传递的参数列表:
在接下来的案例我们会逐一对上面的参数进行详细讲些。
使用 Requests 模拟发送 GET 请求,以请求百度首页为例:
# 导入requests库
import requests
# 要请求的地址 url = "http://www.baidu.com"
# 发起 GET 请求,并将响应结果存储在 res 中,res是一个 responses 对象
res = requests.get(url)
print(res.request.headers)
# 查看请求头信息
print(res.request.body)
# 查看请求正文
print(res.request.url)
# 查看请求url
print(res.request.method)
# 查看请求方法
print(res.content)
# 响应结果的字节码格式,一般用于图片,视频数据等
print(res.encoding)
# 查看响应正文的编码格式
print(res.text)
# 响应结果的字符串格式,非字节码
print(res.status_code)
# 响应结果状态码,200 表示成功
print(r.reason)
# 响应状态码的描述信息,如 OK,NotFound 等
print(res.cookies)
# 获取 cookies print(res.headers) # 查看响应的响应头
print(res.url)
# 查看响应的url如果响应内容中文显示是乱码,在此提供2种解决方案:
import requests
url = "http://www.baidu.com"
res = requests.get(url)
# 方案1:
res.encoding="utf-8" # 如果 res.text 中有中文乱码,修改编码格式为 "utf-8"
print(res.text)
# 方案2:
res.content.decode("utf-8") # 将响应结果的字节码格式转换为 "utf-8" 格式
print(res.text)1)发起携带参数的 GET 请求
来看一下 Request 中 get 方法的定义:
def get(url, params=None, **kwargs):
return request("get", url, params=params, **kwargs)这意味着发起 GET 请求时,允许我们使用 params 关键字参数,参数的类型为字典(dict)。接下来看一个案例:
慕课网(https://www.imooc.com/)首页搜索 “python”,按 F12 –> 点击 NetWork 抓包获取其接口。
我们得到的接口部分信息如下:请求方式:get 请求url:https://www.imooc.com/search/coursesearchconditions?words=python
?words=python问号后面的 word=python 就是我们在发起 get 请求时的要提供的参数,接下来使用 requests 来发起请求:
import requests
# 慕课网首页课程查询接口
url = "https://www.imooc.com/search/coursesearchconditions"
# 查询时携带的参数
payload = { 'words': 'python' }
res = requests.get(url, params=payload) # 发起携带参数的 get 请求
print(res.json()) # 响应内容是 json 格式的字符串,我们使用 res.json() 方法进行解码2)定制请求头
如果你想为请求添加 HTTP 头部,只需要传递一个字典(dict)给 headers 参数即可。例如,我们发起请求时要传递一个 UA(User-Agent)。User-Agent 中文名为用户代理,是Http协议中的一部分。它可以向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标 识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计。
为什么要添加 UA?
在使用 Python 的 Requests 模拟浏览器向服务器发送 Http 请求时,于某些网站会设置对 User-Agent 反爬虫机制,因此我们发送 Http 请求时有必要的加上 User-Agent 来将爬虫程序的UA伪装成某一款浏览器的身份标识。
import requests
url = "https://www.imooc.com/search/coursesearchconditions"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'}
# 查询时携带的参数
payload = { 'words': 'python' }
res = requests.get(url, params=payload, headers=headers)
print(res.json()) # 响应内容是 json 格式的字符串,我们使用 res.json() 方法进行解码
print(res.request.headers) # 查看请求头1)传递 data 参数
当我们要向网页上的一些表单(form)传递数据时,经常需要发起 post 请求。使用 requests 发起 post 请求的方法也非常简单,只需要传递一个字典给 data 参数。
import requests
url = 'http://httpbin.org/post'
payload = {'name': 'joy', 'phone': '400-7865-6666'}
r = requests.post(url=url, data=payload)
print(r.text)运行结果:{ ... "form": { "key2": "value2", "key1": "value1" }, ... }
还可以为 data 参数传入一个元组列表。例如表单中多个元素使用同一个 key 时,可以像下面这样做:
import requests
url = 'http://httpbin.org/post'
payload = (('course', 'Python'), ('course', 'Java'))
r = requests.post(url=url, data=payload)
print(r.text)响应结果:{ ... "form": { "course": [ "Python", "Java" ] }, ... }
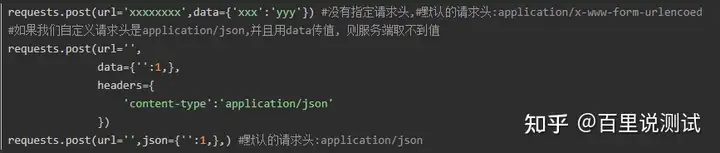
当你想用 data 参数去接收 json 格式的数据,那么需要把请求的数据转换成 json 格式,并且要将请求头设置为 application/json。
import requests, json
url = 'https://api.github.com/some/endpoint'
data = json.dumps({ "some": "data" })
headers = {"Content-Type":"application/json"}
r = requests.post(url, data=data, headers=headers)
print(r.text)2) 传递json参数
可以使用 json 参数直接传递,然后它就会被自动编码
import requests, json
url = "http://119.45.233.102:6677/testgoup/test/json"
data = { 'name': 'jay', 'age': 23 }
r = requests.post(url,json=data)
print(r.text)这里科普一下 json 和 dict(字典)的区别:
(1)字典是一种数据结构,是python中的一种数据类型;它是一种可变类型,可以存储任意类型的数值,以 key:value 的形式存储数据,但是 key 可以是任意可hash的对象 ,在一个字典中不允许出现两个相同的key值,如果出现,后面一个key值会覆盖前面的key值。
(2)Json是一种打包的数据格式,本质上是字符串,也是按照 key:value 来存储数据,key 只能时字符串,且可以有序、重复;必须使用双引号作为key或者值的边界符,不能使用单引号,使用单引号或者不使用引号会使解析错误。可以被解析为字典或者其他形式。
(3)json.loads函数的使用,将字符串转化为字典
import jsona = {'a': '1', 'b': '2', 'c': '3' }print(type(a)) # 输出 <class 'dict'>b = json.loads('{"age": "12"}') # 参数是str行,loads之后,变成dict字典了print(b) # 输出 {'age': '12'}print(type(b)) # 输出 <class 'dict'>(4)json.dumps()函数的使用,将字典转化为字符串
import json# json.dumps()函数的使用,将字典转化为字符串dict1 = {"age": "12"}json_info = json.dumps(dict1)print("dict1的类型:"+str(type(dict1)))print("通过json.dumps()函数处理:")print("json_info的类型:"+str(type(json_info)))
3)传递 from-data 参数:
注意,requests默认是不支持from-data的请求数据的格式的。所以我们要传from-data格式,我们需要安装一个requests的插件:pip install requests_toolbelt -i https://pypi.douban.com/simple
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
method = "post"
url = "http://119.45.233.102:6677/testgoup/test/data"
data = MultipartEncoder({ "name":"张三", "age":"23" })
headers = {"Content-Type":data.content_type}
r = requests.request(method,url,data=data,headers=headers)
print(r.text)4)传递 auth 参数
auth是一种对接口进行鉴权的方式,和cookies和token的作用差不多的。格式:元组,比如:(“账号”,“密码”)
import requests
url = "http://119.45.233.102:6677/testgoup/test/auth"
method = "post"
auth = ("admin","123456")
r = requests.request(method,url,auth=auth)
print(r.text)5)传递 timeout 参数
timeout用于控制响应的时间,如果超过了timeout规定的时间,那么会直接抛出连接失败的错误信息。timeout格式是整数,单位是秒。
import requests
method = "post"
url = "http://119.45.233.102:6677/testgoup/test/json"
data = { "name":"张三", "age":23 }
r = requests.request(method,url,json=data,timeout=10)
print(r.text)6)传递 allow_redirects 参数
是否允许接口重定向。格式:布尔值
7)传递 proxies 参数
在编写爬虫程序时,同一个IP频繁对网站进行访问,可能会被封IP,为了避免这种情况我们就需要用到 proxies 参数来设置代理。proxies 参数可以将代理地址替换为你的IP地址,隐藏自身IP。
proxies 参数类型
proxies = { '协议':'协议://IP:端口号' }
proxies = { 'http':'http://IP:端口号', 'https':'https://IP:端口号', }可以去网上搜索免费的代理IP网站中查找免费代理IP(注意:如果获取到的免费IP地址无效就会报错):
# 使用免费普通代理IP访问测试网站: http://httpbin.org/get
import requests
url = 'http://httpbin.org/get'
headers = {'User-Agent':'Mozilla/5.0'} # 定义代理,在代理IP网站中查找免费代理IP
proxies = { 'http':'http://182.116.239.37:9999', 'https':'https://182.116.239.37:9999' }
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text print(html)这里推荐几个免费代理网站,可自行尝试:
8)传递 verify 参数
当我们请求https协议的接口的时候,如果它的证书过期了,我们就可以使用这个参数verify,设置为Fasle不检查证书,忽略证书的问题,继续请求。
TGU登录接口测试,登录接口信息如下:
地址:http://119.45.233.102:2244/testgoup/login
类型:post
请求头:application/json
请求参数:{ "phone": "133********", "password": "e10adc3949ba59abbe56e057f20f883e", "type": 1 }
返回值:{ "code": 1, "data": { "nickName": "liuyanzu666", "token": "eyJ..." }, "message": "登录成功!" }使用requests测试登录接口:
import requests
loginUrl = 'http://119.45.233.102:2244/testgoup/login'
method='post'
data = { "phone": "133********", "password": "e10adc3949ba59abbe56e057f20f883e", "type": 1 }
r = requests.request(method=method, url=loginUrl, json=data)
print(r.text)由于需要登录后才能获取到用户信息,在获取用户信息时需要传入登录后返回的token。完整代码如下:
import requests
loginUrl = 'http://119.45.233.102:2244/testgoup/login'
method='post'
data = { "phone": "133********", "password": "e10adc3949ba59abbe56e057f20f883e", "type": 1 } #登录接口
r = requests.request(method=method, url=loginUrl, json=data) #
print(r.text)
token = r.json()['data']['token']
# 获取用户信息接口
userinfoUrl = 'http://119.45.233.102:2244/testgoup/user/getUserInfo'
headers = {'token': token}
r = requests.request(method='get', url=userinfoUrl, headers=headers)
print(r.text)上述实战代码均在 TestGoUp 网站开展测试,并对账号进行了加密,可自行注册获取自己的账号进行测试。
上面代码中的 token = r.json()['data']['token'] 里有一个细节这里要展开叙述一下。来看一下登录接口返回的响应结果,也就是 print(r.text) 的值:
{ "code": 1, "data": { "nickName": "liuyanzu666", "token": "eyJhbGci..." # token太长了,这里删掉部分数据 }, "message": "登录成功!" }
咋一看这是一个python字典类型的数据,有的同学可能说这是 json 类型的数据。到底是字典还是json类型的数据,我们使用 type() 方法对 r.text 进行判断即可。
print(type(r.text)) # 返回结果是 <class 'str'>
返回结果居然是 str 类型的数据。现在我们要从 r.text 中获取 token 值,如果我们将它从 str 类型转换成字典类型,那么就可以通过 token 键获取对应的 toekn 值了。这里就引出了我们要讲的知识点:
Python序列化和反序列化
序列化:将Python中字典类型的数据转换成json格式的字符串,以便进行存储和传输。
反序列化:将json格式的字符串转换成Python的字典类型数据,便于对其分析和处理。
我们可以使用 json 模块来实现序列化和反序列化:
import json
# 字典类型的数据
data = { "name": "张三", "age": 18 }
# 使用 json.dumps() 进行序列化:字典-->字符串
res = json.dumps(data)
print(res) # 输出结果:{"name": "\u5f20\u4e09", "age": 18}
print(type(res)) # 输出结果:<class 'str'>
# 使用 json.loads() 进行反序列化:字符串-->字典
res2 = json.loads(res)
print(res2) # 输出结果:{'name': '张三', 'age': 18}
print(type(res2)) # 输出结果:<class 'dict'>上面阐述了使用 python 进行序列化和反序列化的方法,但是在登录接口中获取token值的时候 ,我们并没有使用 json.loads() 进行反序列化,而是使用 “token = r.json()[‘data’][‘token’],也就是r.json()` 方法。
也就是说在上面的代码中,获取token我们可以使用两种方法:
... r = requests.request(method=method, url=loginUrl, json=data)
方法一: token = json.loads(r.text)['data']['token']
方法二: token = r.json()['data']['token'] ...