处理Python关于Dict的错误KeyError的办法挺多,不过就记下了2个:
方法一:使用setdefault()设置默认值,如
data.setdefault('error', 0)
方法二:导入collections,使用defaultdict方法
data = collections.defaultdict(list, data)

学习笔记
处理Python关于Dict的错误KeyError的办法挺多,不过就记下了2个:
方法一:使用setdefault()设置默认值,如
data.setdefault('error', 0)
方法二:导入collections,使用defaultdict方法
data = collections.defaultdict(list, data)
本文转自:https://www.yiichina.com/tutorial/1405
官方文档:http://www.yiichina.com/doc/guide/2.0/db-query-builder
文章涉及where、 addParams 、filterWhere 、andWhere、orWhere、 andFilterWhere()、 orFilterWhere()、andFilterCompare()
但是格式是一样的
字符串格式,例如:'status=1'
哈希格式,例如: ['status' => 1, 'type' => 2]
操作符格式,例如:['like', 'name', 'test']
字符串和哈希格式很好理解,我们来看看操作符格式,因为操作符格式可以组成相对复杂的查询语句
最简单的就是官方给的例子
$status = 10;
$search = 'yii';
$query->where(['status' => $status]);
if (!empty($search)) {
$query->andWhere(['like', 'title', $search]);
}
生成的语句就是
... WHERE (`status` = 10) AND (`title` LIKE '%yii%')
操作符格式
[操作符, 操作数1, 操作数2, ...]

第一个参数是操作符
操作符包括and、or、 like、in、 between等
第二个第三个都是操作数
第一种最简单的就是上面提到的例子
andWhere(['like', 'title','搜索的标题']);
生成的语句
... WHERE (`status` = 10) AND (`title` LIKE '%yii%')
第二种
addWhere(['and', 'id=1', 'name=2']);
生成的语句
... WHERE id=1 AND name=2
第三种
addWhere(['and', 'type=1', ['or', 'id=1', 'id=2']]);
生成的语句
... WHERE type=1 AND (id=1 OR id=2);
第四种
->andWhere(['or like','name',['哈哈','苦苦']]);
生成的语句
WHERE `name` LIKE '%哈哈%' OR `name` LIKE '%苦苦%';
第五种
addWhere(['or',['like','name','哈哈'],['like','title','苦苦']]);//操作符格式的嵌套
生成的语句
... WHERE (`status`=1) AND ((`name` LIKE '%哈哈%') OR (`title` LIKE '%苦苦%'))
$query->andWhere(new Expression(‘FIND_IN_SET(‘1,size’)’));+
生成的语句
… WHERE id=1 AND FIND_IN_SET(1, size)
//size的值:1,2,3,4,5
一共两步:
1、利用 Python项目管理器 2.1 搭建运行环境
(1)每一个项目都配了一个”venv”的环境,执行命令时需要使用完整路径;
(2)如若不能正常执行,请查看”log”,添加需要的模块,直到应用可以跑起来
2、映射域名
原文链接:https://www.cnblogs.com/allan-king/p/5807659.html
Django 模型是与数据库相关的,与数据库相关的代码一般写在 models.py 中,Django 支持 sqlite3, MySQL, PostgreSQL等数据库,只需要在settings.py中配置即可,不用更改models.py中的代码,丰富的API极大的方便了使用。 1、数据库的连接方式以及设置: 在Django中默认使用的数据库类型是sqlite3,如果想要使用其他数据库就需要在settings中设置数据库的连接方式:
# Database# https://docs.djangoproject.com/en/1.10/ref/settings/#databases# sqlite3数据库连接方式# DATABASES = {# 'default': {# 'ENGINE': 'django.db.backends.sqlite3',# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),# }# }# MySQL数据库连接方式DATABASES ={'default': {'ENGINE': 'django.db.backends.mysql','NAME':'dbname','USER': 'root','PASSWORD': 'xxx','HOST': '','PORT': '',}}
2、开始创建表
数据需要在models.py文件中创建
classUserInfo(models.Model):# CharField类型不能为空,最少要指定一个长度user =models.CharField(max_length=32)email =models.EmailField(max_length=32)pwd =models.CharField(max_length=32)user_type =models.ForeignKey('UserType')classUserType(models.Model):nid =models.AutoField(primary_key=True)caption =models.CharField(max_length=16)
注:在创建外键的时候直接写上UserType和’UserType’的区别就是python程序从上到下解释的顺序问题,如果把UserType这个类写到下面就会没事了
运行Djando项目程序,执行命令创建数据:
python3 manage.py makemigrations python3 manage.py migrate
创建表的的参数:
1、models.AutoField 自增列 = int(11)
如果没有的话,默认会生成一个名称为 id 的列,如果要显示的自定义一个自增列,必须将给列设置为主键 primary_key=True。
2、models.CharField 字符串字段
必须 max_length 参数
3、models.BooleanField 布尔类型=tinyint(1)
不能为空,Blank=True
4、models.ComaSeparatedIntegerField 用逗号分割的数字=varchar
继承CharField,所以必须 max_lenght 参数
5、models.DateField 日期类型 date
对于参数,auto_now = True 则每次更新都会更新这个时间;auto_now_add 则只是第一次创建添加,之后的更新不再改变。
6、models.DateTimeField 日期类型 datetime
同DateField的参数
7、models.Decimal 十进制小数类型 = decimal
必须指定整数位max_digits和小数位decimal_places
8、models.EmailField 字符串类型(正则表达式邮箱) =varchar
对字符串进行正则表达式
9、models.FloatField 浮点类型 = double
10、models.IntegerField 整形
11、models.BigIntegerField 长整形
integer_field_ranges = {
'SmallIntegerField': (-32768, 32767),
'IntegerField': (-2147483648, 2147483647),
'BigIntegerField': (-9223372036854775808, 9223372036854775807),
'PositiveSmallIntegerField': (0, 32767),
'PositiveIntegerField': (0, 2147483647),
}
12、models.IPAddressField 字符串类型(ip4正则表达式)
13、models.GenericIPAddressField 字符串类型(ip4和ip6是可选的)
参数protocol可以是:both、ipv4、ipv6
验证时,会根据设置报错
14、models.NullBooleanField 允许为空的布尔类型
15、models.PositiveIntegerFiel 正Integer
16、models.PositiveSmallIntegerField 正smallInteger
17、models.SlugField 减号、下划线、字母、数字
18、models.SmallIntegerField 数字
数据库中的字段有:tinyint、smallint、int、bigint
19、models.TextField 字符串=longtext
20、models.TimeField 时间 HH:MM[:ss[.uuuuuu]]
21、models.URLField 字符串,地址正则表达式
22、models.BinaryField 二进制
23、models.ImageField 图片
24、models.FilePathField 文件
更多字段
1、null=True
数据库中字段是否可以为空
2、blank=True
django的 Admin 中添加数据时是否可允许空值
3、primary_key = False
主键,对AutoField设置主键后,就会代替原来的自增 id 列
4、auto_now 和 auto_now_add
auto_now 自动创建---无论添加或修改,都是当前操作的时间
auto_now_add 自动创建---永远是创建时的时间
5、choices
GENDER_CHOICE = (
(u'M', u'Male'),
(u'F', u'Female'),
)
gender = models.CharField(max_length=2,choices = GENDER_CHOICE)
6、max_length
7、default 默认值
8、verbose_name Admin中字段的显示名称
9、name|db_column 数据库中的字段名称
10、unique=True 不允许重复
11、db_index = True 数据库索引
12、editable=True 在Admin里是否可编辑
13、error_messages=None 错误提示
14、auto_created=False 自动创建
15、help_text 在Admin中提示帮助信息
16、validators=[]
17、upload-to
更多参数
执行成功状态:
1 bogon:django_modes01 zk$ python3 manage.py makemigrations 2 Migrations for 'app01': 3 app01/migrations/0001_initial.py: 4 - Create model UserInfo 5 - Create model UserType 6 - Add field user_type to userinfo 7 bogon:django_modes01 zk$ python3 manage.py migrate 8 Operations to perform: 9 Apply all migrations: admin, app01, auth, contenttypes, sessions 10 Running migrations: 11 Rendering model states... DONE 12 Applying contenttypes.0001_initial... OK 13 Applying auth.0001_initial... OK 14 Applying admin.0001_initial... OK 15 Applying admin.0002_logentry_remove_auto_add... OK 16 Applying app01.0001_initial... OK 17 Applying contenttypes.0002_remove_content_type_name... OK 18 Applying auth.0002_alter_permission_name_max_length... OK 19 Applying auth.0003_alter_user_email_max_length... OK 20 Applying auth.0004_alter_user_username_opts... OK 21 Applying auth.0005_alter_user_last_login_null... OK 22 Applying auth.0006_require_contenttypes_0002... OK 23 Applying auth.0007_alter_validators_add_error_messages... OK 24 Applying auth.0008_alter_user_username_max_length... OK 25 Applying sessions.0001_initial... OK 状态
如果提示:No changes detected
需要在settings.py的配置文件检测一下有没有注册app
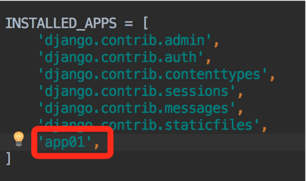
在MySQL中就可以看到生成的表:
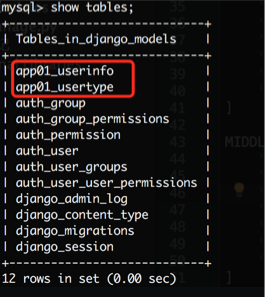
外键关系:

3.开始创建数据
创建数据的时候有两种方式:
第一种方式:
obj = models.表名(字段名='***') obj.save()
第二种方式:
models.表名.objects.create(字段名='***')
在views.py中写入数据:
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
def index(request):
# 创建用户类型表
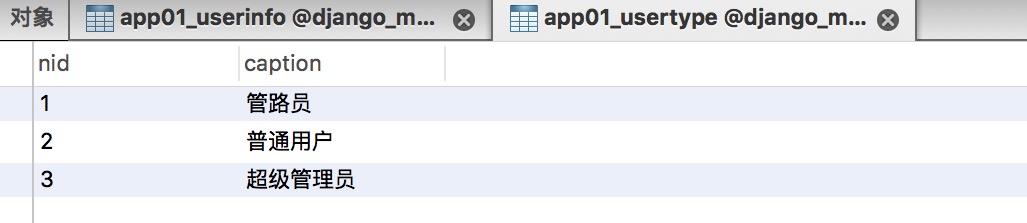
models.UserType.objects.create(caption='管路员')
models.UserType.objects.create(caption='普通用户')
models.UserType.objects.create(caption='超级管理员')
# 创建用户信息表
user_info_dict_1 = {'user': 'ales',
'email': 'alex@qq.com',
'pwd': 123,
'user_type': models.UserType.objects.get(nid=1),
}
user_info_dict_2 = {'user': 'eric',
'email': 'eric@qq.com',
'pwd': 123,
'user_type_id': 2,
}
models.UserInfo.objects.create(**user_info_dict_1)
models.UserInfo.objects.create(**user_info_dict_2)
print('yes')
return HttpResponse('ok')
运行Django 项目访问指定文件创建数据:

4、了不起的双下划线之外键正向查找和基本操作
# 增
#
# models.Tb1.objects.create(c1='xx', c2='oo') 增加一条数据,可以接受字典类型数据 **kwargs
# obj = models.Tb1(c1='xx', c2='oo')
# obj.save()
# 查
#
# models.Tb1.objects.get(id=123) # 获取单条数据,不存在则报错(不建议)
# models.Tb1.objects.all() # 获取全部
# models.Tb1.objects.filter(name='seven') # 获取指定条件的数据
# 删
#
# models.Tb1.objects.filter(name='seven').delete() # 删除指定条件的数据
# 改
# models.Tb1.objects.filter(name='seven').update(gender='0') # 将指定条件的数据更新,均支持 **kwargs
# obj = models.Tb1.objects.get(id=1)
# obj.c1 = '111'
# obj.save() # 修改单条数据
基本操作
# 获取个数
#
# models.Tb1.objects.filter(name='seven').count()
# 大于,小于
#
# models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值
# models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
# in
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
# contains
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven")
# range
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
# 其他类似
#
# startswith,istartswith, endswith, iendswith,
# order by
#
# models.Tb1.objects.filter(name='seven').order_by('id') # asc
# models.Tb1.objects.filter(name='seven').order_by('-id') # desc
# limit 、offset
#
# models.Tb1.objects.all()[10:20]
# group by
from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=1).values('id').annotate(c=Count('num'))
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id"
进阶操作(双下划线)
单表查询:
# ret = models.UserType.objects.all() # print(ret.query) # ret.query后台返回的是查询的sql语句
结果:
SELECT `app01_usertype`.`nid`, `app01_usertype`.`caption` FROM `app01_usertype`
获取查询结果的类型:
ret = models.UserType.objects.all() print(type(ret), ret)
可以看到类型是一个QuerySet类型,后面是所有的对象,每一个元素就是一个对象,可以循环拿出每一次的数据:
ret = models.UserType.objects.all()
print(type(ret), ret)
for item in ret:
print(item)
其结果就是每一次循环出来的结果的对象:
UserType object UserType object UserType object
每一个对象都代表一个数据,要出去这些数据如下:
ret = models.UserType.objects.all()
print(type(ret), ret)
for item in ret:
print(item, item.nid, item.caption)
取出的结果:
UserType object 1 管路员 UserType object 2 普通用户 UserType object 3 超级管理员
从结果看出每次输出item的时候都是一个对象(一行数据中所有的对象,对象中封装了所有的数据),在modes中有__str__方法(返回什么,就输出什么,就是查看方便), 在python2.7中叫__unicode__如果在UserType这个类里面使用这个方法:
class UserType(models.Model):
nid = models.AutoField(primary_key=True)
caption = models.CharField(max_length=16)
def __str__(self):
return '%s-%s' % (self.nid, self.caption)
然后重新访问下:
1-管路员 1 管路员 2-普通用户 2 普通用户 3-超级管理员 3 超级管理员
就可以看到每一个对象都看到了返回的相对应的参数了。
查询单个字段:
ret = models.UserType.objects.all().values('nid')
print(type(ret), ret)
结果查询出nid字段对应的所有的数据 :
<QuerySet [{'nid': 1}, {'nid': 2}, {'nid': 3}]>可以看查询的sql语句,用query方法:
ret = models.UserType.objects.all().values('nid')
print(type(ret), ret.query)
查询的结果:
SELECT `app01_usertype`.`nid` FROM `app01_usertype`
当通过values循环取值的时候,如下:
ret = models.UserType.objects.all().values('nid')
print(type(ret), ret.query)
for item in ret:
print(item, type(item))
结果:
SELECT `app01_usertype`.`nid` FROM `app01_usertype`{'nid': 1} <class'dict'>{'nid': 2} <class'dict'>{'nid': 3} <class'dict'>通过结果可以看出,最外部是QuerySet,内部元素封装了一个是封装了这一行所有数据的对象,另外只拿到了某几列的字典!
当通过values_list循环取值的时候,如下:
ret = models.UserType.objects.all().values_list('nid')
print(type(ret), ret)
查询结果:
<QuerySet [(1,), (2,), (3,)]>依然是queryset,但是结果就是列表中包含的元组,values和values_list的区别就是:values取的是字典类型,values_list把内部元素变成元组了。通过for循环更直观,如下:
ret = models.UserType.objects.all().values_list('nid')
print(type(ret), ret)
for item in ret:
print(type(item), item)
哔哩哔哩(bilibili、B站) 视频下载
很多时候我们在土豆网、B站、快手、秒拍、腾讯视频、爱奇艺、优酷等网站上看了一些好玩的,有用的,有意思的小视频或电影想下载观看或分享给朋友,却由于格式问题,无法播放。今天把私藏多年的几个在线视频下载器分享给大家,其中VSO Downloader是软件,需要下载,其他几个是在线解析地址。支持下载200+个视频网站的视频。VSO Downloade可以下载98%的在线视频。堪称下载神器。
V视频下载助手帮助您一键下载各大网站视频,支持爱奇艺视频下载、优酷视频下载、土豆视频下载、腾讯视频下载、迅雷看看视频等等网站。

2、视频鱼
视频鱼提供在线视频下载,支持bilibili、芒果tv、cntv、新浪、土豆,酷6、秒拍、搜狐等网站的视频下载。

3、小视频下载
小视频下载网站支持主流视频网站下载,如优酷、腾讯视频、爱奇艺、搜狐视频等
https://bilibili.online-downloader.com/index-Chinese
提供了从YouTube, FaceBook, Vimeo, 优酷, Yahoo等200多个视频站点下载视频的最快捷,最简单的方法,提供从200多个视频站点中保存的视频的最佳质量。

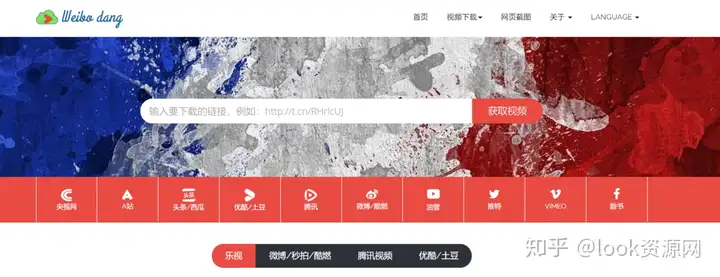
5、微博党
可以看到网站支持优酷/土豆、 腾讯、网易公开课/音乐、知乎、音悦台、头条、微博,甚至是汤博等视频下载。
下载方式很简单,直接复制链接,点击获取地址即可。
这个网站的稳定性,是我用的最好的一个,提供的几个网站视频几乎都可以获得下载地址,非常方便。
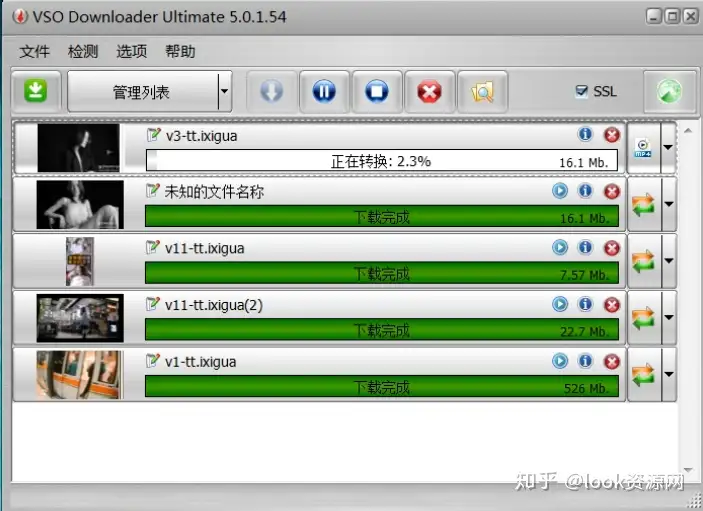
6、VSO Downloader https://www.lookzy.cn/8662.html
VSO Downloader破解版是一款功能强大,使用非常方便简单的批量下载网页视频工具,会在右下角提示你智能识别视频并可以直接下载。VSO Downloader破解版支持youtube视频下载,而且也能够正确下载土豆、优酷网站中的视频,支持所有的浏览器,全自动侦测网页视频播放。
2. 可以直接使用 文档伴侣(没错就是我)。国产免费版mathpix,可以提取PDF文档或图片中的数学公式、表格、图片、文字等内容,然后转为 markdown 和word文档。欢迎使用。
3. 他来了,他来了,Mathpix拜拜了~~~文字、表格、公式图片识别神器V0.1测试版 – 知乎 (zhihu.com)
Typora正式版收费之后一直用不收费的Typora beta版,直到前不久Typora beta版被禁止使用,不得不另找替代品。
诚然,markdown编辑器有非常多,算上带有markdown编辑功能/支持markdown语法的笔记软件更是数不胜数,但是像Typora这样优秀且单纯的WYSIWYG markdown编辑器并不多。因此我在寻找Typora替代品的时候限定了以下范围:
经过一番搜索和对知乎上各类答案的总结归纳以及实际使用体验,满足以上限制条件的markdwon编辑器/解决方案有:
P.S.
这个回答参考的一篇markdown编辑器测评:
查找资料过程中整理的带有markdown编辑功能的免费笔记软件:
Effie, Joplin, Leanote, Mybase, Notable, Simplenote, Trilium
使用VLOOKUP函数可以查找数据,但想要做一个查询数据的应用则可以使用FILTER+FIND+ISNUMBER三个函数,下面这个组合搭建一个简易数据的查询系统
=FILTER(A2:A10,ISNUMBER(FIND(E2,A2:A10)))<iframe src="//player.bilibili.com/player.html?aid=216096237&bvid=BV1Wa411M7jC&cid=778020207&page=1" scrolling="no" border="0" frameborder="no" framespacing="0" allowfullscreen="true"> </iframe>情境:请根据学生的入口成绩和出口成绩来确定指标的高低线
思路:先对数据进行分段,通过调控梯度得到各分段的比率,进一步得到相应的最值
创建云函数say()
module.exports = {
_before: function () { // 通用预处理器
},
say(message){
return {
errorCode: 0,
data: "Hello I'm uniCloud!"+message
}
}
}调用云函数say()
export default {
data() {
return {
href: 'https://uniapp.dcloud.io/component/README?id=uniui'
}
},
methods: {
async callco(){//异步调用
const co1 = uniCloud.importObject("co1")//导入云函数
let res = await co1.say("Hello world!~")//调用
uni.showModal({
content:JSON.stringify(res),
showCancel:false
})
}
}
}<template>
<view class="container">
<button @click="callco">呼叫服务器</button>
</view>
</template>